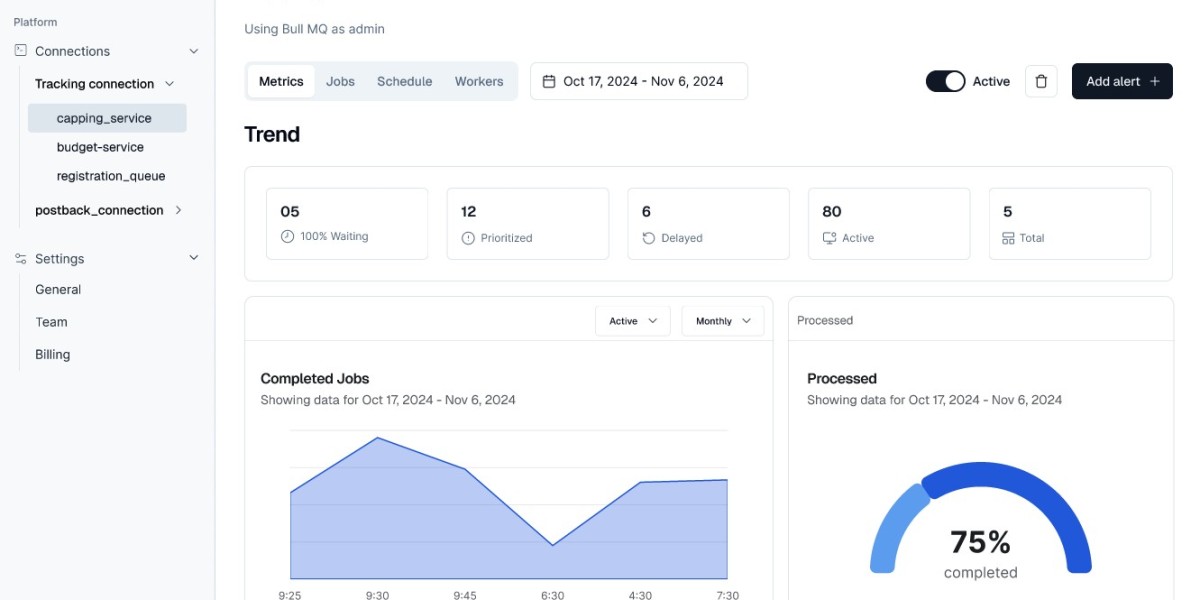
In high-performance Node.js applications, BullMQ is a popular choice for handling background tasks and queue-based job processing. Whether you're sending emails, processing video files, or running scheduled data imports, BullMQ ensures asynchronous task execution is efficient and reliable. However, to ensure things don’t silently fail, it's essential to Monitor BullMQ queues closely.
This article will explore how to monitor BullMQ queues, the metrics to watch, tools you can use, and best practices to maintain healthy and performant job systems.
Why Monitor BullMQ Queues?
Monitoring isn’t just about tracking success—it’s about proactively identifying failures, bottlenecks, and performance issues. Proper queue monitoring helps you:
Detect stuck or slow jobs
Prevent queue overflows or job pile-ups
Measure throughput and job latency
Quickly debug job failures
Optimize resource usage and worker allocation
Improve reliability and maintain SLAs
What to Monitor in BullMQ Queues
To effectively monitor BullMQ queues, focus on the following dimensions:
1. Job Counts by Status
Track the number of jobs in each queue with statuses like:
waitingactivecompletedfaileddelayedstuckorpaused
A sudden spike in failed or waiting jobs might indicate underlying issues.
2. Job Duration and Processing Time
Measure how long it takes for a job to be processed from creation to completion. High durations can signal slow worker performance or resource constraints.
3. Throughput (Jobs per Minute)
Gauge how many jobs are being processed over time. Drops in throughput may mean workers are overloaded, offline, or malfunctioning.
4. Failure Rates
High failure rates should trigger immediate attention. Monitor error messages and failure types to pinpoint root causes.
5. Worker Health
Ensure your workers are connected, active, and responsive. Dead or stalled workers are a common cause of queue stagnation.
6. Queue Lag
Lag is the time a job waits before being picked up. Monitor this to understand whether jobs are being processed quickly or getting delayed.
Tools to Monitor BullMQ Queues
✅ BullMQ UI (Official Dashboard)
Developed by the creators of BullMQ.
Offers real-time visibility into all job statuses.
Lets you retry, remove, or inspect jobs.
Includes advanced flow/parent-child job visualizations.
Ideal for production systems with multiple queues.
✅ Bull Board
Lightweight, open-source dashboard.
Supports basic queue and job inspection.
Good for local development or staging environments.
✅ Custom Prometheus + Grafana Integration
Export custom metrics from your worker apps (e.g., queue size, job durations, error counts).
Build dashboards tailored to your business needs.
Add alerting rules based on job or queue thresholds.
✅ Logging + APM Tools (Datadog, Sentry, New Relic)
Use structured logs and distributed tracing to monitor job execution paths.
Integrate failure logs and performance data.
How to Set Up Queue Monitoring in BullMQ
1. Expose Metrics from Workers
Add endpoints or emit custom metrics to track queue stats using Redis and BullMQ’s Queue class methods like:
2. Use Scheduled Health Checks
Monitor if queue lengths exceed acceptable limits or if job retries spike. Schedule checks with alerting thresholds.
3. Log Critical Events
Use BullMQ event listeners like completed, failed, or stalled to log job results and worker behavior.
4. Integrate Alerts
Set up Slack, PagerDuty, or email alerts for critical scenarios:
X jobs failed in Y minutes
Queue length above threshold
No job completions for Z minutes
Best Practices for Monitoring BullMQ Queues
Set Timeouts and Retries: Avoid endless stuck jobs.
Segment Queues by Task Type: Helps isolate issues and maintain granularity.
Tag and Log Job Context: Make debugging easier by storing user IDs, order IDs, or error contexts.
Visualize Trends Over Time: Not all issues are immediate—monitor trends to plan for scaling.
Automate Recovery: Automatically restart crashed workers or notify teams of anomalies.
Final Thoughts
To run background jobs at scale, it’s not enough to just queue them—you must monitor BullMQ queues proactively. By combining real-time dashboards, custom metrics, and robust alerting, you ensure your system is not just working, but thriving.